

Orchestrator 구축 이후 Takeover 및 Auto Failover를 설정하겠습니다.
Orchestrator 구축 1편 : https://jhdatabase.tistory.com/134
[MySQL - Orchestrator 구축] part 1
Orchestrator란? MySQL용 복제 토폴로지 관리자로써 고가용성 및 복제 관리 툴입니다. 체인을 위아래로 훑으면서 마스터와 슬레이브를 찾아 MySQL 환경의 복제 토폴로지를 검색하는 기능을 제공합니다
jhdatabase.tistory.com
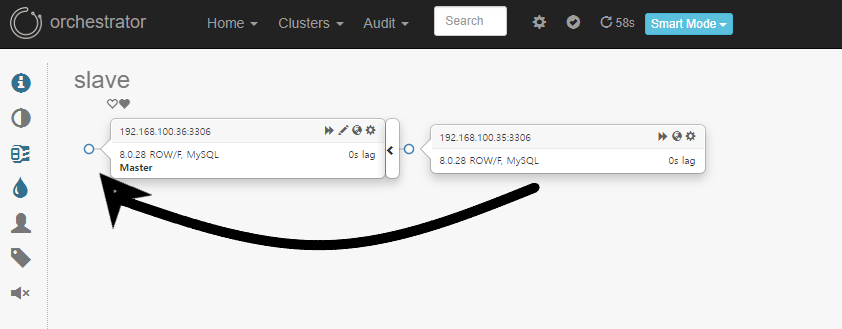
Takeover Test
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for source to send event
Master_Host: 192.168.100.35
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql.000009
Read_Master_Log_Pos: 94146
Relay_Log_File: mysql-relay-bin.000002
Relay_Log_Pos: 2522
Relay_Master_Log_File: mysql.000009
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
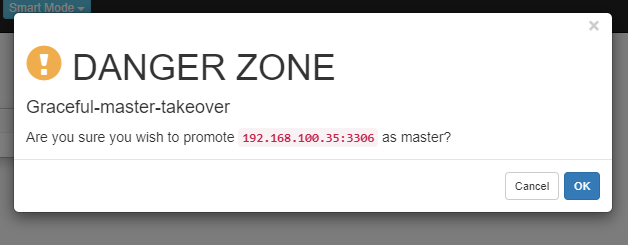
■ OK 클릭
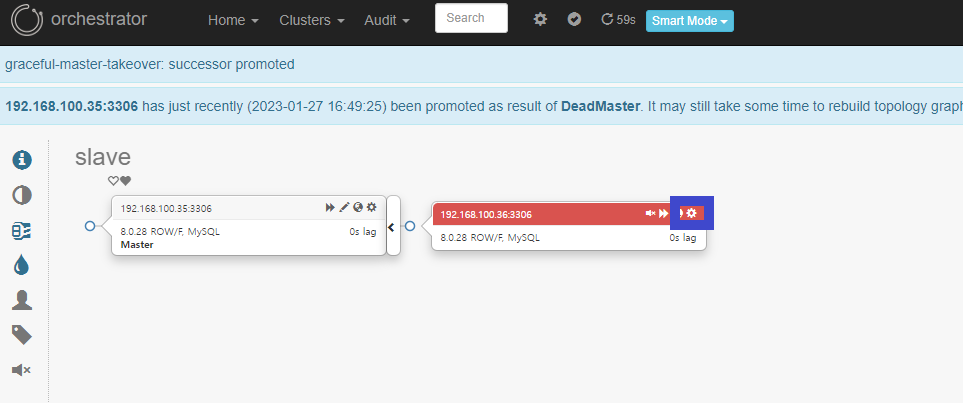
■ Slave노드의 톱니바퀴 클릭
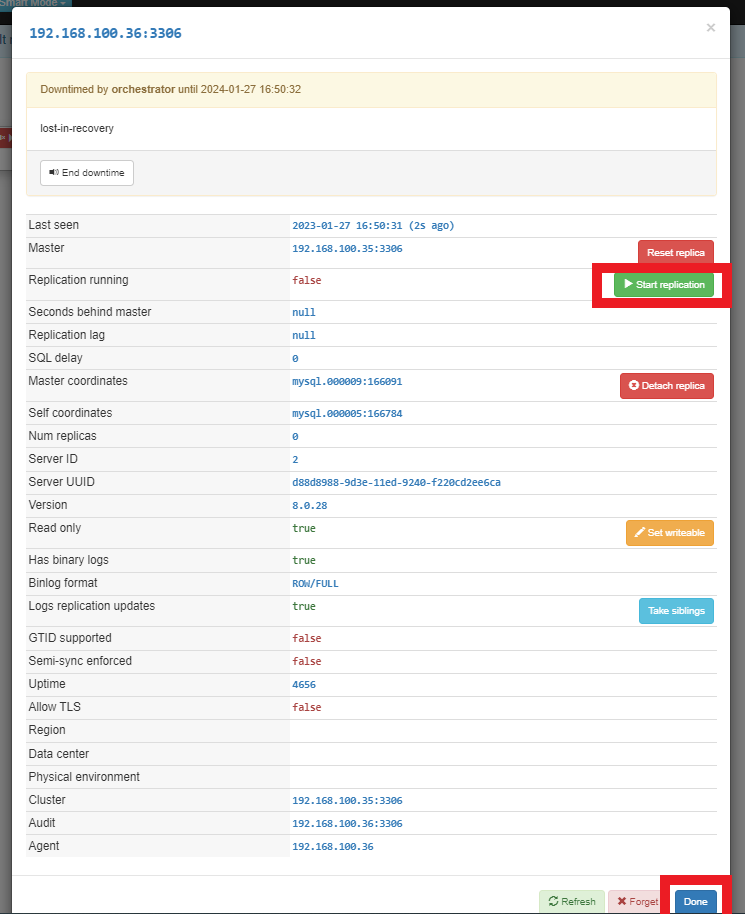
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for source to send event
Master_Host: 192.168.100.36
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql.000005
Read_Master_Log_Pos: 175623
Relay_Log_File: mysql-relay-bin.000002
Relay_Log_Pos: 762
Relay_Master_Log_File: mysql.000005
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Failover Test (Manual)
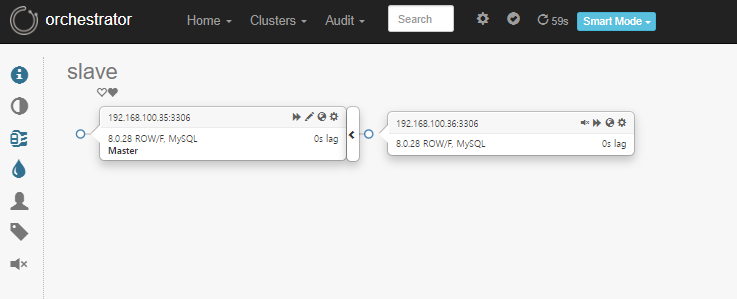
■ Master DB kill
[root@master ~]# ps -ef | grep mysql
mysql 5178 53757 0 15:32 pts/1 00:00:39 mysqld --user=mysql
root 6114 6077 0 Jan26 ? 00:06:31 /usr/local/percona/pmm2/exporters/mysqld_exporter --collect.auto_increment.columns --collect.binlog_size --collect.custom_query.hr --collect.custom_query.hr.directory=/usr/local/percona/pmm2/collectors/custom-queries/mysql/high-resolution --collect.custom_query.lr --collect.custom_query.lr.directory=/usr/local/percona/pmm2/collectors/custom-queries/mysql/low-resolution --collect.custom_query.mr --collect.custom_query.mr.directory=/usr/local/percona/pmm2/collectors/custom-queries/mysql/medium-resolution --collect.engine_innodb_status --collect.engine_tokudb_status --collect.global_status --collect.global_variables --collect.heartbeat --collect.info_schema.clientstats --collect.info_schema.innodb_cmp --collect.info_schema.innodb_cmpmem --collect.info_schema.innodb_metrics --collect.info_schema.innodb_tablespaces --collect.info_schema.processlist --collect.info_schema.query_response_time --collect.info_schema.tables --collect.info_schema.tablestats --collect.info_schema.userstats --collect.perf_schema.eventsstatements --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.slave_status --collect.standard.go --collect.standard.process --exporter.conn-max-lifetime=55s --exporter.global-conn-pool --exporter.max-idle-conns=3 --exporter.max-open-conns=3 --log.level=warn --web.listen-address=:42002
root 8903 53757 0 16:55 pts/1 00:00:00 grep --color=auto mysql
[root@master ~]# kill -9 5178
■ 장애 감지 확인
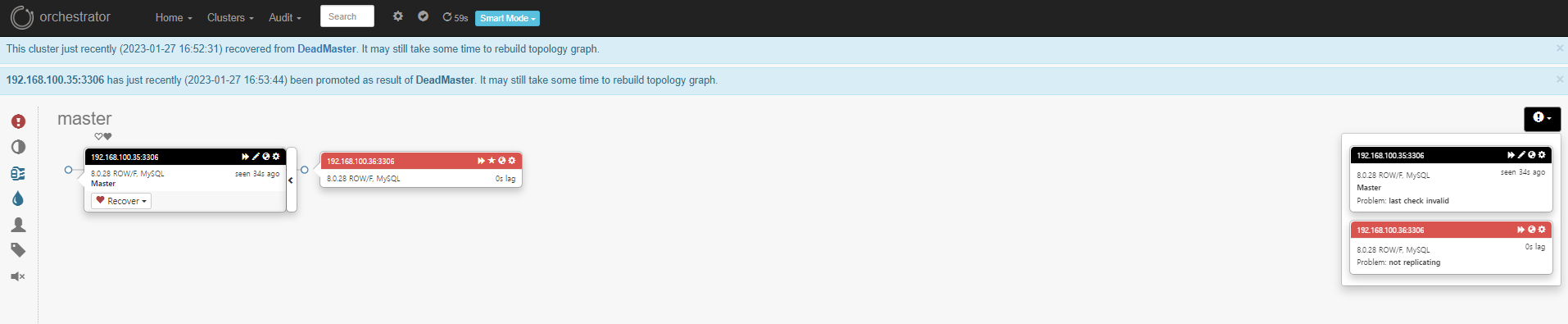
■ orchestrator log
[root@orchestrator tmp]# tail -200f /tmp/recovery.log
...
Detected DeadMaster on 192.168.100.35:3306. Affected replicas: 1

■ 기존 Slave DB가 Master로 승격
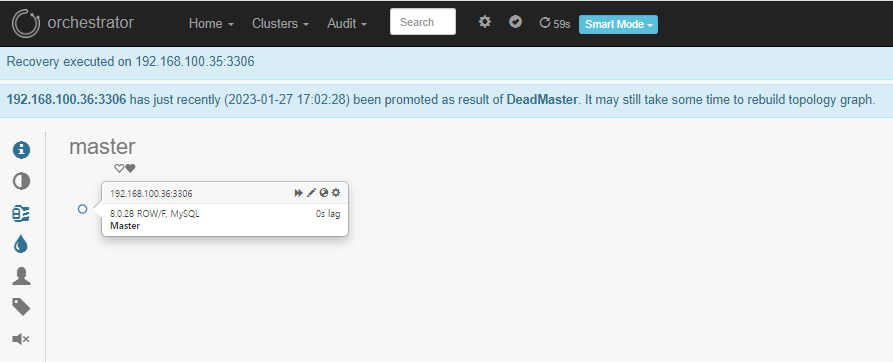

■ Binlog pos와 파일명 확인
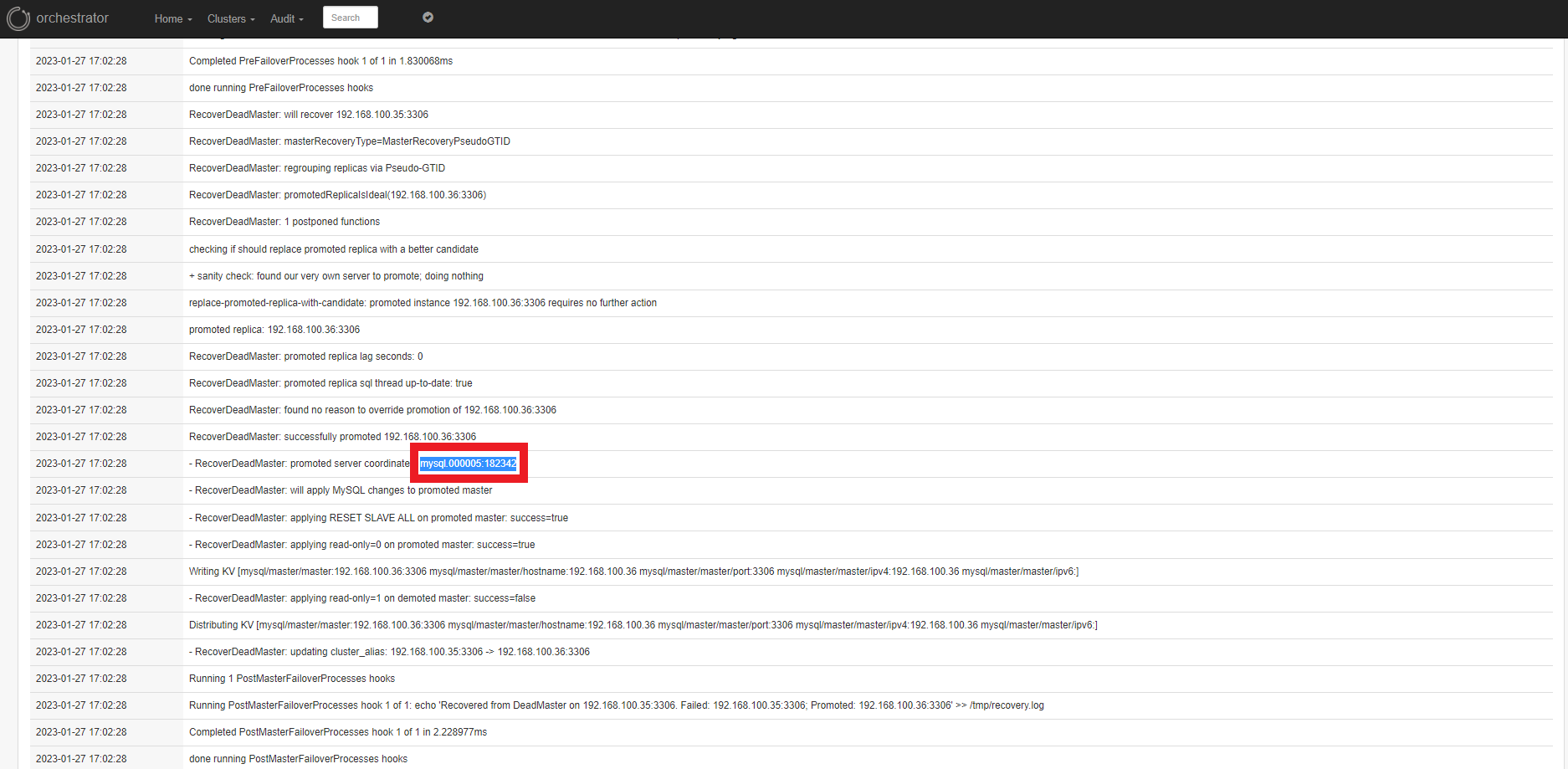
CHANGE MASTER TO MASTER_HOST='192.168.100.36', MASTER_USER='repl',MASTER_PASSWORD='repl',MASTER_PORT=3306,MASTER_LOG_FILE='mysql.000005', MASTER_LOG_POS=182342,MASTER_CONNECT_RETRY=10;
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for source to send event
Master_Host: 192.168.100.36
Master_User: repl
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: mysql.000005
Read_Master_Log_Pos: 200602
Relay_Log_File: mysql-relay-bin.000002
Relay_Log_Pos: 18582
Relay_Master_Log_File: mysql.000005
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
■ 재반영 확인
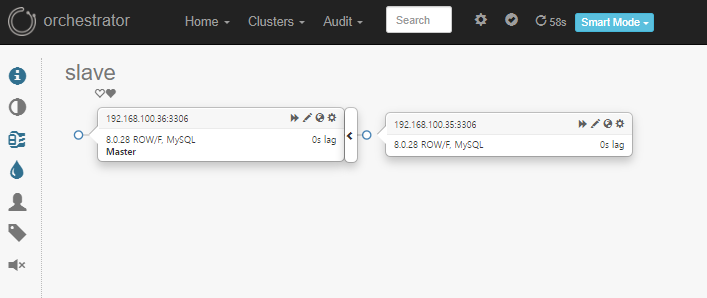
Auto Failover 설정
Config Docs : https://github.com/openark/orchestrator/blob/master/docs/configuration-recovery.md
GitHub - openark/orchestrator: MySQL replication topology management and HA
MySQL replication topology management and HA. Contribute to openark/orchestrator development by creating an account on GitHub.
github.com
Automated Recovery 실행 될 때 승격이 되는 노드를 전부(*) 또는 특정 1개 노드(인스턴스) 를 지정할 수 있습니다. (/etc/hosts에 기재된 alias로 수정)
[root@orchestrator ~]# vi /usr/local/orchestrator/orchestrator.conf.json
"RecoveryPeriodBlockSeconds": 30,
"RecoveryIgnoreHostnameFilters": [],
"RecoverMasterClusterFilters": [
"*"
],
"RecoverIntermediateMasterClusterFilters": [
"*"
],
## RecoverMasterClusterFilters => Master 장애 대해서 자동 복구할 클러스터 를 지정
## PromotionIgnoreHostnameFilters => Slave 노드 중에서 Master 로 Promote(승격) 대상에서 제외 할 Hostname(노드) 를 입력, 입력 하지 않으면 가용한 Slave 노드 중에서 승격
## RecoverIntermediateMasterClusterFilters => 해당 파라미터는 복제 구성에서 중간 Master 에 대한 복구 여부를 설정하는 파라미터 입니다.
## RecoveryPeriodBlockSeconds => 장애가 발생 후 자동 복구가 되면 위의 파라미터에 지정한 시간 동안은 자동 복구를 차단 하게 됩니다 Default 3600 (초), 한번 장애가 발생 되어서 자동 복구가 수행 된다면 3600초 안에는 장애가 발생 되어도 자동 복구가 수행되지 않음을 의미
■ Master kill
[root@master ~]# ps -ef | grep mysql
mysql 7025 5876 0 10:12 pts/0 00:00:36 mysqld --user=mysql
root 13864 5876 0 12:46 pts/0 00:00:00 grep --color=auto mysql
[root@master ~]# kill -9 7025
■ Slave(192.168.100.36)이 Master노드로 승격됨
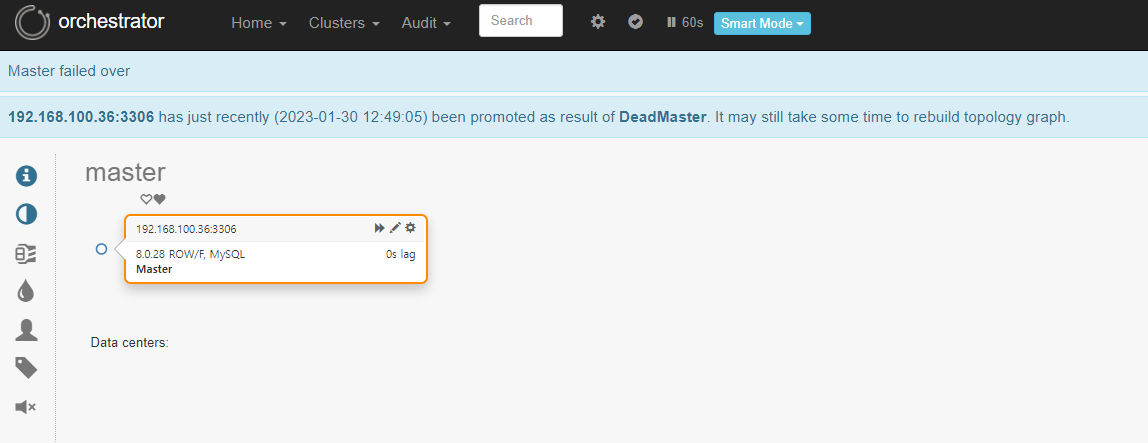
■ orchestrator log
Detected DeadMaster on 192.168.100.35:3306. Affected replicas: 1
Will recover from DeadMaster on 192.168.100.35:3306
Recovered from DeadMaster on 192.168.100.35:3306. Failed: 192.168.100.35:3306; Promoted: 192.168.100.36:3306
(for all types) Recovered from DeadMaster on 192.168.100.35:3306. Failed: 192.168.100.35:3306; Successor: 192.168.100.36:3306
참고
MySQL Orchestrator - HA(High Availability) - 2 - 리팩토링 Failover Automated Recovery
hoing.io
'DataBase > MySQL & MariaDB' 카테고리의 다른 글
| [MySQL - 로컬 컴퓨터 to MySQL 서버 데이터 이관] use.MySQL workbench (0) | 2023.02.10 |
|---|---|
| [MySQL - Orchestrator VIP설정 part 3 use. Keepalived] (0) | 2023.02.05 |
| [MySQL - Orchestrator 구축] part 1 (2) | 2023.02.05 |
| [MySQL - Read/Write Split 부하분산 구성] use. ProxySQL (0) | 2023.01.27 |
| [MySQL - Tunner 설치] (0) | 2022.11.05 |